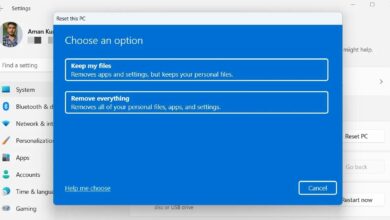
Ever wondered why your computer slows down or crashes unexpectedly? A reliable system monitor can be your digital detective, uncovering hidden issues before they escalate.
What Is a System Monitor and Why It Matters

A system monitor is a software tool designed to track, analyze, and report the performance and health of a computer system or network. It plays a critical role in maintaining optimal functionality, preventing downtime, and ensuring security across both personal and enterprise environments. Whether you’re managing a single desktop or an entire cloud infrastructure, having real-time visibility into system behavior is non-negotiable in today’s digital landscape.



Core Functions of a System Monitor
At its heart, a system monitor performs several essential tasks that keep your IT environment running smoothly. These include tracking CPU usage, memory consumption, disk I/O, network activity, and process behavior. By continuously gathering this data, the tool provides administrators with actionable insights.
- Real-time performance tracking
- Alert generation for anomalies
- Historical data logging for trend analysis
For example, if a server’s CPU usage spikes to 95% for more than five minutes, the system monitor can trigger an alert, allowing IT staff to investigate potential bottlenecks or malicious processes.
Types of System Monitoring
System monitoring isn’t a one-size-fits-all solution. Different environments require different monitoring strategies. The main types include:
- Hardware Monitoring: Tracks physical components like temperature, fan speed, and power supply status.
- Software Monitoring: Observes application performance, service availability, and process execution.
- Network Monitoring: Analyzes bandwidth usage, latency, packet loss, and connection status.
- Cloud & Virtualization Monitoring: Focuses on VM performance, container health, and cloud resource allocation.
Each type serves a unique purpose but often overlaps in comprehensive monitoring platforms. For instance, Nagios offers integrated solutions covering all these areas, making it a go-to choice for enterprise IT teams.
“Monitoring is not about collecting data—it’s about understanding what that data means for your business.” — DevOps Engineer, Google Cloud
Key Metrics Tracked by a System Monitor
To truly understand system health, a system monitor focuses on specific performance indicators. These metrics provide a quantitative view of how well a system is functioning and help identify trends over time.
CPU Usage and Load Average
CPU usage measures the percentage of processing power being utilized at any given moment. A consistently high CPU usage (above 80%) may indicate inefficient code, too many background processes, or even a malware infection. The load average, typically shown as 1-minute, 5-minute, and 15-minute averages, reflects the number of processes waiting for CPU time.
On Unix-like systems, the top or htop command provides real-time CPU metrics. A system monitor automates this observation, logging data and generating alerts when thresholds are exceeded. For example, setting a threshold of 75% CPU usage for 10 minutes can prompt an automatic investigation.
Memory (RAM) Utilization
Memory monitoring tracks how much RAM is being used, how much is cached, and how much is available. When physical memory is exhausted, systems begin using swap space on the disk, which is significantly slower and can lead to performance degradation.
A good system monitor will differentiate between active, inactive, and cached memory. It can also detect memory leaks—applications that continuously consume memory without releasing it. Tools like Netdata offer real-time memory graphs with drill-down capabilities for individual processes.
Disk I/O and Storage Health
Disk input/output operations are crucial for system responsiveness. High disk usage (especially sustained above 90%) can cause lag, slow boot times, and application timeouts. A system monitor tracks read/write speeds, IOPS (Input/Output Operations Per Second), and disk queue length.
Additionally, modern monitors integrate SMART (Self-Monitoring, Analysis, and Reporting Technology) data to predict hard drive failures. For example, if a drive shows an increasing number of reallocated sectors, the system monitor can warn administrators before catastrophic failure occurs.
Top 7 System Monitor Tools in 2024
Choosing the right system monitor can make or break your IT operations. Below is a curated list of the most powerful and widely used tools, each offering unique strengths depending on your needs.
1. Nagios XI – The Enterprise Standard
Nagios XI is one of the most respected names in system monitoring. It offers comprehensive monitoring for servers, applications, services, and network protocols. With a robust plugin architecture, it supports thousands of third-party extensions.
- Real-time alerting via email, SMS, or Slack
- Customizable dashboards and reporting
- Support for distributed monitoring across global networks
Nagios excels in environments where reliability and customization are paramount. However, its interface can be complex for beginners. Learn more at Nagios XI Official Page.
2. Zabbix – Open Source Powerhouse
Zabbix is a free, open-source monitoring solution trusted by organizations worldwide. It provides real-time monitoring of networks, servers, virtual machines, and cloud services. One of its standout features is its built-in automation for discovery and scaling.
- Auto-discovery of network devices and services
- Advanced alert correlation and dependency mapping
- Support for distributed and cloud-native architectures
Zabbix uses a centralized database (MySQL, PostgreSQL) to store metrics and offers a web-based frontend for easy access. Its scalability makes it ideal for large enterprises. Visit Zabbix.com for documentation and downloads.
3. Datadog – Cloud-Native Excellence
Datadog is a SaaS-based monitoring platform designed for modern, cloud-driven environments. It integrates seamlessly with AWS, Azure, Google Cloud, Kubernetes, and Docker, making it a favorite among DevOps teams.
- Unified observability across logs, metrics, and traces
- AI-powered anomaly detection
- Real-time collaboration features
Datadog’s strength lies in its ease of setup and rich visualization tools. While it’s subscription-based, the ROI in reduced downtime often justifies the cost. Explore it at Datadoghq.com.
4. Prometheus – For DevOps and Kubernetes
Prometheus is an open-source monitoring and alerting toolkit originally built at SoundCloud. It’s now a CNCF (Cloud Native Computing Foundation) graduate project and is widely adopted in Kubernetes environments.
- Pull-based monitoring model with HTTP scraping
- Powerful query language (PromQL)
- Highly scalable and modular design
Prometheus stores time-series data efficiently and integrates with Grafana for stunning visualizations. It’s particularly effective for microservices monitoring. Get started at Prometheus.io.
5. PRTG Network Monitor – All-in-One Solution
Developed by Paessler, PRTG is a Windows-based system monitor that combines network, server, and application monitoring in a single platform. It uses a sensor-based model, where each sensor monitors a specific aspect (e.g., CPU, ping, HTTP).
- Over 200 sensor types available
- Intuitive drag-and-drop dashboard
- Supports SNMP, WMI, SSH, and packet sniffing
PRTG is user-friendly and ideal for small to mid-sized businesses. The free version allows up to 100 sensors, making it accessible for testing. Learn more at Paessler.com.
6. New Relic – Full-Stack Observability
New Relic offers a comprehensive observability platform that covers everything from infrastructure to end-user experience. It’s particularly strong in application performance monitoring (APM).
- Real-user monitoring (RUM) for web apps
- Distributed tracing for microservices
- AI-driven insights and root cause analysis
New Relic’s platform helps developers identify performance bottlenecks in code, database queries, and third-party APIs. It’s a premium tool with a steep learning curve but unmatched depth. Visit Newrelic.com for a free trial.
7. Netdata – Real-Time, Zero-Config Monitoring
Netdata stands out for its real-time performance and zero-configuration setup. It’s designed to be installed on any Linux system and immediately starts collecting over 1,000 metrics.
- Sub-second data collection intervals
- Beautiful, interactive web dashboard
- Automatic anomaly detection
Netdata is perfect for developers and sysadmins who want instant visibility without complex setup. It’s open-source and free for personal use. Check it out at Netdata.cloud.
How to Choose the Right System Monitor
With so many options available, selecting the best system monitor can be overwhelming. The decision should be based on your environment, technical expertise, budget, and long-term goals.
Assess Your Environment
Start by evaluating your infrastructure. Are you monitoring a single server, a local network, or a hybrid cloud setup? For on-premise systems, tools like Zabbix or PRTG may be ideal. For cloud-native applications, Datadog or New Relic offer better integration.
Also consider the scale. A small business with 10 servers doesn’t need the complexity of Nagios, while a large enterprise with global data centers will benefit from its distributed architecture.
Consider Integration and Scalability
The best system monitor should integrate seamlessly with your existing tools—whether it’s Slack for alerts, Jenkins for CI/CD, or Grafana for dashboards. Look for APIs and plugin ecosystems that allow customization.
Scalability is equally important. As your infrastructure grows, your monitoring solution should grow with it. Prometheus and Zabbix are highly scalable, while Netdata is better suited for individual nodes or small clusters.
Evaluate Cost vs. Value
While open-source tools like Zabbix and Prometheus are free, they may require more manpower for setup and maintenance. Commercial tools like Datadog and New Relic come with a price tag but offer managed services, faster support, and advanced features.
Calculate the total cost of ownership (TCO), including training, hardware, and potential downtime. Sometimes paying for a premium tool saves more in the long run by preventing outages.
Setting Up a System Monitor: Step-by-Step Guide
Implementing a system monitor doesn’t have to be daunting. Follow this structured approach to ensure a smooth deployment.
Step 1: Define Monitoring Objectives
Before installing any software, clarify what you want to monitor and why. Common objectives include:
- Reducing system downtime
- Improving application performance
- Ensuring compliance with SLAs
- Detecting security threats early
Having clear goals helps you choose the right metrics and tools.
Step 2: Install and Configure the Monitoring Agent
Most system monitors require an agent to be installed on the target machine. For example, in Zabbix, you’d install the Zabbix agent on a Linux server using:
sudo apt install zabbix-agent
Then, configure the /etc/zabbix/zabbix_agentd.conf file with the server IP and hostname. Restart the service, and the agent will begin sending data.
Step 3: Set Up Alerts and Notifications
Alerts are the lifeblood of any system monitor. Configure thresholds for critical metrics. For instance:
- Email alert if CPU > 90% for 5 minutes
- Slack message if disk space < 10%
- PagerDuty escalation if a service is down for 10 minutes
Use alert grouping to avoid notification fatigue. Tools like Prometheus Alertmanager can deduplicate and route alerts intelligently.
Advanced Features of Modern System Monitors
Today’s system monitors go beyond basic metric tracking. They offer intelligent features that transform raw data into actionable insights.
AI-Powered Anomaly Detection
Modern tools like Datadog and New Relic use machine learning to detect unusual patterns. Instead of relying on static thresholds, they learn normal behavior and flag deviations.
For example, if a database query suddenly takes 5x longer than usual, the system monitor can alert you—even if the absolute time is still below a predefined threshold. This proactive approach catches issues before users notice.
Automated Root Cause Analysis
When an alert fires, time is critical. Advanced system monitors can perform automated root cause analysis by correlating events across systems.
If a web server crashes, the tool might check related services: Did the database go down first? Was there a spike in traffic? Did a recent deployment occur? By analyzing dependencies, it can pinpoint the likely cause, reducing mean time to resolution (MTTR).
Custom Dashboards and Reporting
Visualizing data is key to understanding system health. Tools like Grafana allow you to build custom dashboards with real-time charts, gauges, and heatmaps.
You can create dashboards for different teams—IT, management, developers—each showing relevant metrics. Scheduled reports can be emailed weekly, providing a snapshot of system performance and uptime.
Common Challenges and How to Overcome Them
Even with the best tools, system monitoring comes with challenges. Recognizing these pitfalls early can save time and resources.
Alert Fatigue
Too many alerts desensitize teams. If every minor fluctuation triggers a notification, important warnings get ignored.
Solution: Implement smart alerting. Use dynamic thresholds, alert suppression during maintenance windows, and escalation policies. Group related alerts and use tools like Opsgenie to manage on-call rotations.
Data Overload
Collecting thousands of metrics can lead to information overload. Not all data is valuable.
Solution: Focus on key performance indicators (KPIs). Define what “normal” looks like and prioritize monitoring those metrics. Use data sampling and retention policies to manage storage costs.
Security and Privacy Risks
Monitoring tools have access to sensitive system data. If compromised, they can become entry points for attackers.
Solution: Secure your monitoring infrastructure. Use encrypted communication (HTTPS, TLS), strong authentication, and role-based access control (RBAC). Regularly audit logs and update software to patch vulnerabilities.
Future Trends in System Monitoring
The field of system monitoring is evolving rapidly, driven by advancements in AI, cloud computing, and edge devices.
Rise of AIOps
Artificial Intelligence for IT Operations (AIOps) is transforming how we monitor systems. By combining big data and machine learning, AIOps platforms can predict failures, automate responses, and optimize performance.
For example, an AIOps tool might detect a memory leak pattern and automatically restart the affected service before it crashes. Gartner predicts that by 2025, 30% of large enterprises will use AIOps and digital experience monitoring technologies.
Edge Monitoring
As IoT devices and edge computing grow, monitoring must extend beyond data centers. Edge nodes—like sensors, gateways, and remote servers—require lightweight, low-latency monitoring solutions.
Tools like Telegraf and lightweight agents are being optimized for edge environments, where bandwidth and power are limited. Real-time analytics at the edge reduce the need to send all data to the cloud.
Serverless and Function Monitoring
With the rise of serverless architectures (e.g., AWS Lambda, Azure Functions), traditional monitoring models don’t apply. You can’t monitor a server that doesn’t exist.
New tools are emerging to track function execution time, cold starts, invocation rates, and error rates. Platforms like Thundra and Epsagon specialize in serverless observability, providing deep insights into ephemeral workloads.
What is a system monitor?
A system monitor is a software tool that tracks the performance, availability, and health of computer systems, networks, and applications. It collects metrics like CPU usage, memory, disk I/O, and network activity to help identify issues and optimize performance.
Why do I need a system monitor?
You need a system monitor to prevent downtime, detect security threats, improve performance, and ensure your IT infrastructure runs smoothly. It provides real-time visibility and historical data for informed decision-making.
Are free system monitoring tools reliable?
Yes, many free tools like Zabbix, Prometheus, and Netdata are highly reliable and used by enterprises worldwide. However, they may require more technical expertise to set up and maintain compared to commercial alternatives.
Can a system monitor detect malware?
While not a replacement for antivirus software, a system monitor can detect unusual behavior—like sudden CPU spikes or unexpected network connections—that may indicate malware activity. It serves as an early warning system.
How do I reduce alert fatigue from my system monitor?
To reduce alert fatigue, set intelligent thresholds, use alert grouping, suppress non-critical alerts during off-hours, and implement escalation policies. Focus on actionable alerts that require immediate attention.
In conclusion, a system monitor is no longer a luxury—it’s a necessity in today’s digital world. Whether you’re managing a single server or a global cloud network, the right monitoring tool provides visibility, control, and peace of mind. From open-source powerhouses like Zabbix to AI-driven platforms like Datadog, the options are vast. The key is to choose a solution that aligns with your environment, goals, and budget. As technology evolves, so too will the capabilities of system monitors, with AIOps, edge computing, and serverless monitoring shaping the future. By staying informed and proactive, you can ensure your systems remain fast, secure, and reliable.
Further Reading: